Some databases can indeed use an index as primary table store. The Oracle database calls this concept index-organized tables (IOT), other databases use the term clustered index. In this section, both terms are used to either put the emphasis on the table or the index characteristics as needed.
An index-organized table is thus a B-tree index without a heap table. This results in two benefits: (1) it saves the space for the heap structure; (2) every access on a clustered index is automatically an index-only scan.
索引组织表以主键顺序组织物理数据存储,索引结构中的每个叶节点(Leaf Nodes)都存储着完整的行数据。对应的主键被称为聚簇索引(Clustered Indexes),除此之外的索引称为二级索引(Secondary Indexes)。
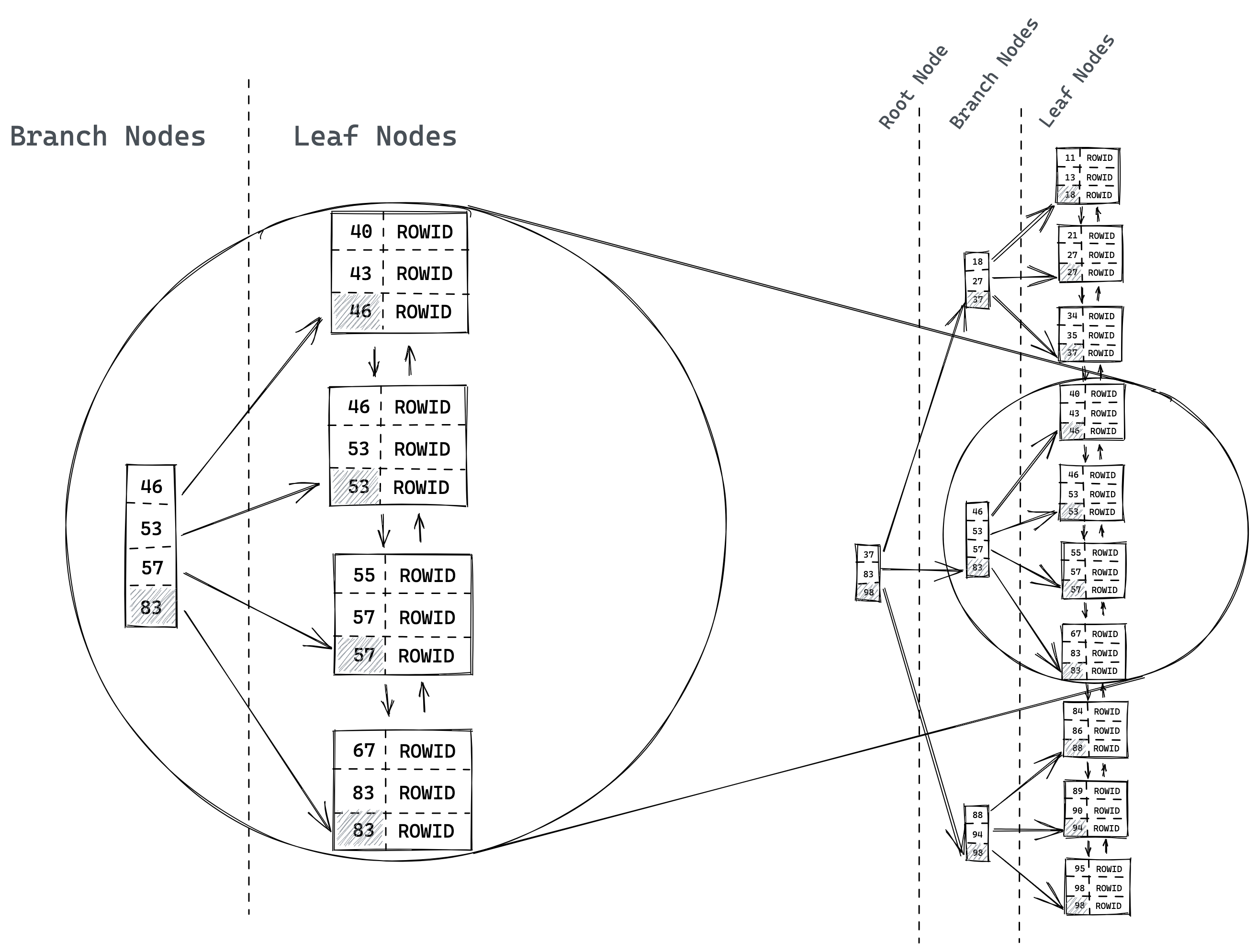
Figure 1: b-tree-structure
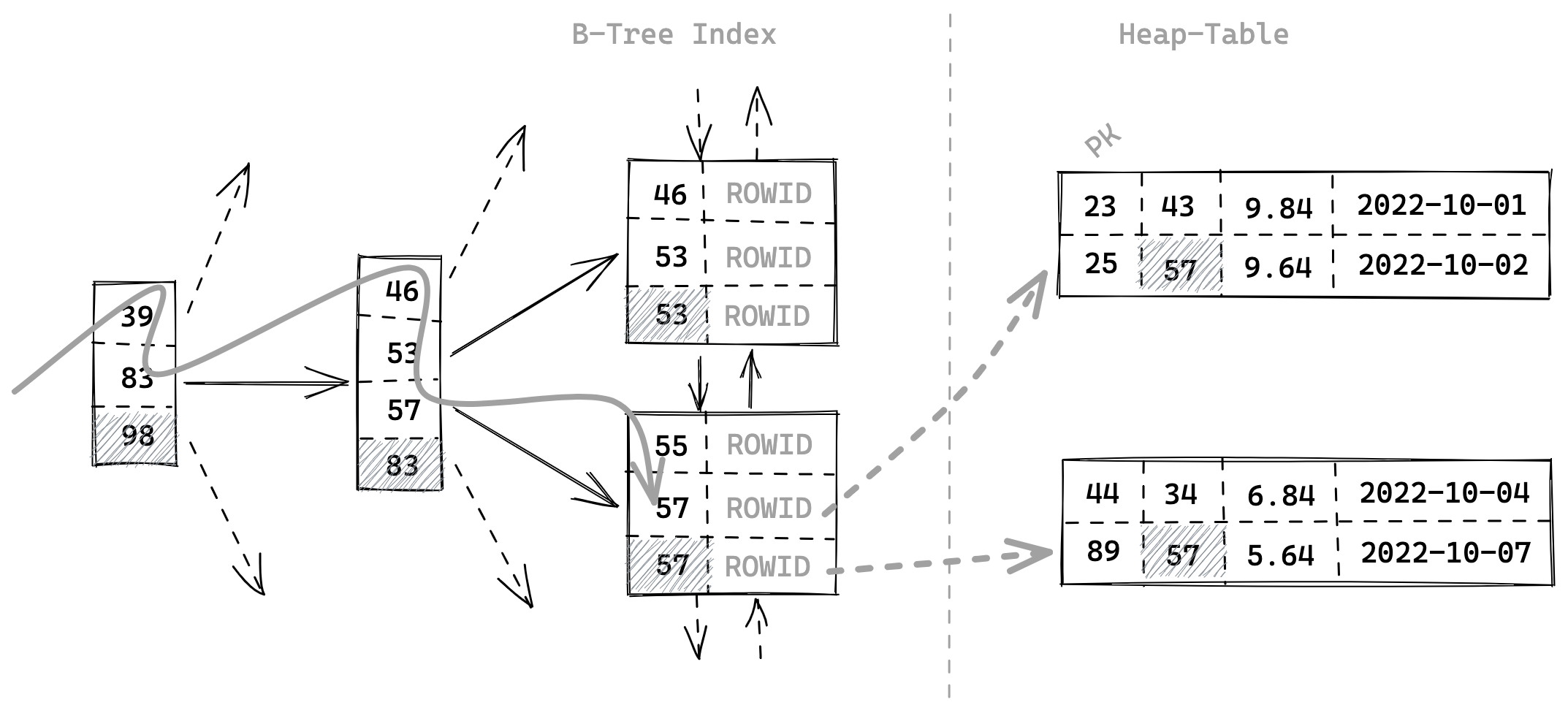
Figure 2: index-based-access-on-a-heap-table
B-Tree 的上级 leaf nodes 存储的是下级 leaf nodes 中列值的最大值,可以从图中看出最底层的 leaf nodes 存储的是 ROWID,可以据此查找到堆表中的位置。
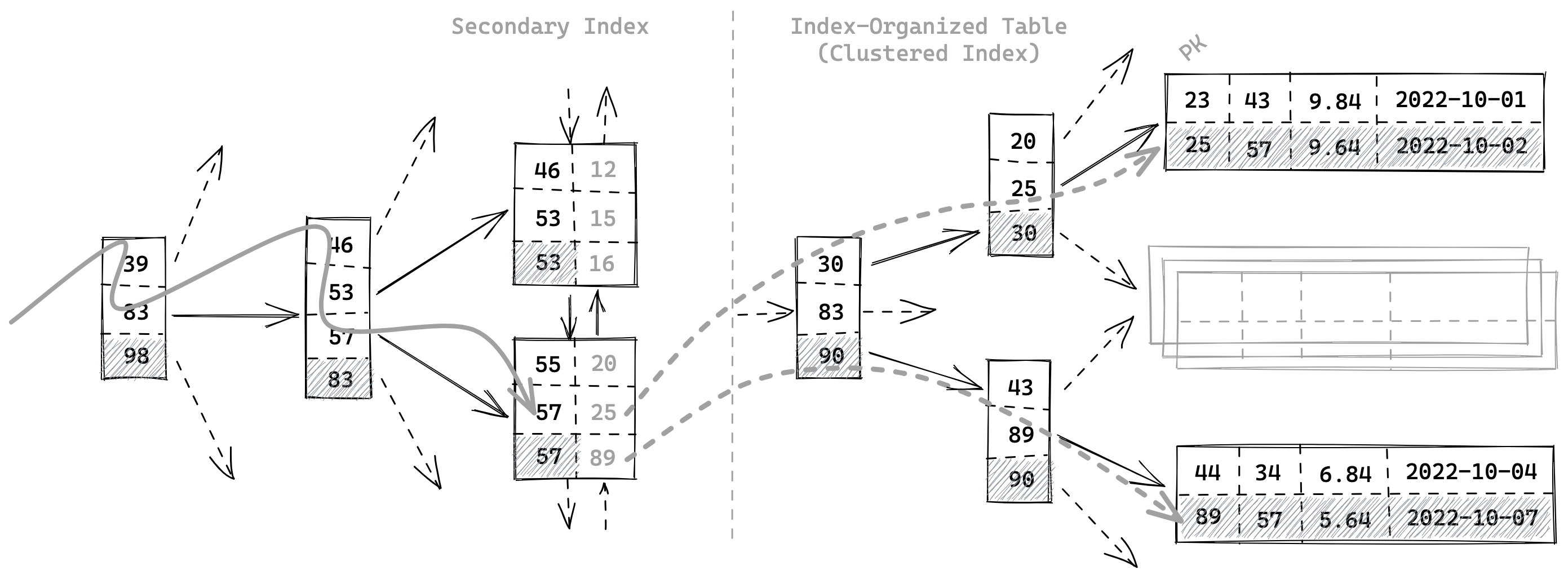
Figure 3: secondary-index-on-an-IOT
聚簇索引
- 在 MySQL 中通常主键即为「聚簇索引」;若没有定义主键,则第一个
NOT NULL UNIQUE列是聚集索引;若没有NOT NULL UNIQUE列,InnoDB 会创建一个隐藏的 row-id 作为聚集索引。 - 聚簇索引是按照索引顺序对物理记录排序,存储完整的行记录。
二级索引
- 除主键外的其他列上新建的索引都是二级索引。
- 二级索引的排序与物理记录的排序不一致,存储的是该列本身排序后的值和主键。
索引组织表的缺点
图 secondary-index-on-an-IOT 就是索引组织表中,二级索引获取数据的流程。再次根据主键在索引组织表中遍历查找就叫做「回表」。
索引组织表的好处
- 可以节省堆表占用的空间
- 访问聚簇索引可以直接获取数据(即「覆盖索引」)
- 二级索引需要回表,即需要根据二级索引的叶节点内的主键,再对主键形成的聚簇索引进行遍历,查找到具体的记录。