B-Tree 和 B+ Tree 的不同
| B-Tree | B+Tree |
|---|---|
| All internal nodes and leaf nodes contain data pointers along with keys. | Only leaf nodes contain data pointers along with keys, internal nodes contain keys only. |
| There are no duplicate keys. | Duplicate keys are present in this, all internal nodes are also present at leaves. |
| Leaf nodes are not linked to each other. | Leaf nodes are linked to each other. |
| Sequential access of nodes is not possible. | All nodes are present at leaves, so sequential access is possible just like a linked list. |
| Searching for a key is slower. | Searching is faster. |
| For a particular number of entries, the height of the B-tree is larger. | The height of the B+ tree is lesser than B-tree for the same number of entries. |
堆表 (Heaps: Table without Clustered Indexes)
A heap is a table without a clustered index. One or more nonclustered indexes can be created on tables stored as a heap. Data is stored in the heap without specifying an order. Usually data is initially stored in the order in which is the rows are inserted into the table, but the Database Engine can move data around in the heap to store the rows efficiently; so the data order cannot be predicted. To guarantee the order of rows returned from a heap, you must use the ORDER BY clause. To specify a permanent logical order for storing the rows, create a clustered index on the table, so that the table is not a heap.
堆表就是含有一列或者多列无聚簇索引的表,其中的数据存储无序。通常数据是按照初始化的顺序存储,但数据库引擎会为了更高效的数据插入,将原有数据移动到别处来释放空间给新的数据。因此,数据的顺序是不确定的,为了保证数据的顺序,可以在查询的时候使用 ORDER BY 关键字进行排序。要保证数据物理存储的数据,就需要建立聚簇索引,这个时候就不是堆表了。
When a table is stored as a heap, individual rows are identified by reference to an 8-byte row identifier (RID) consisting of the file number, data page number, and slot on the page (FileID:PageID:SlotID). The row ID is a small and efficient structure.
ROWID 是文件编号、数据页编号以及页面上的卡槽组成。(FileID:PageID:SlotID)
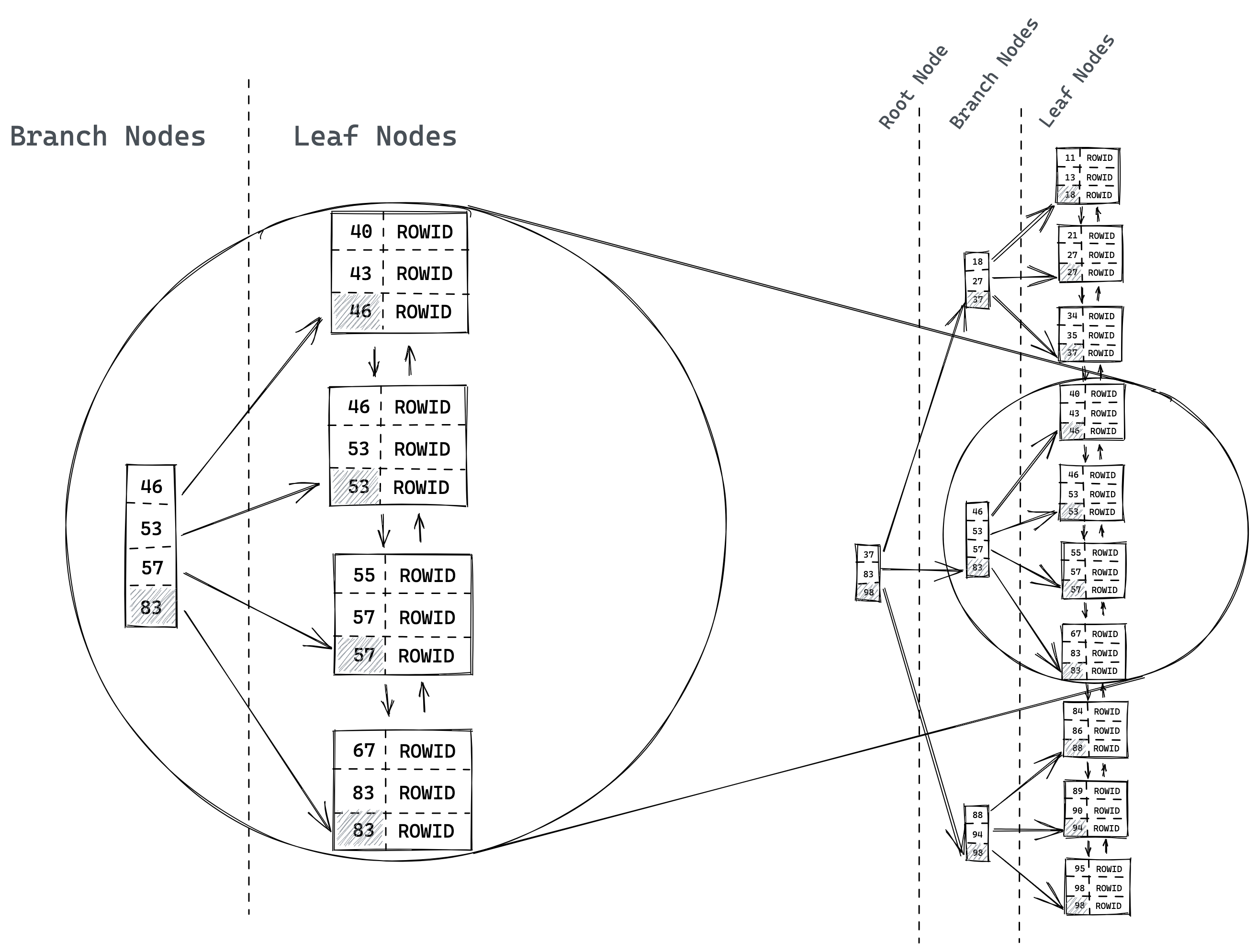
Figure 1: b-tree-structure
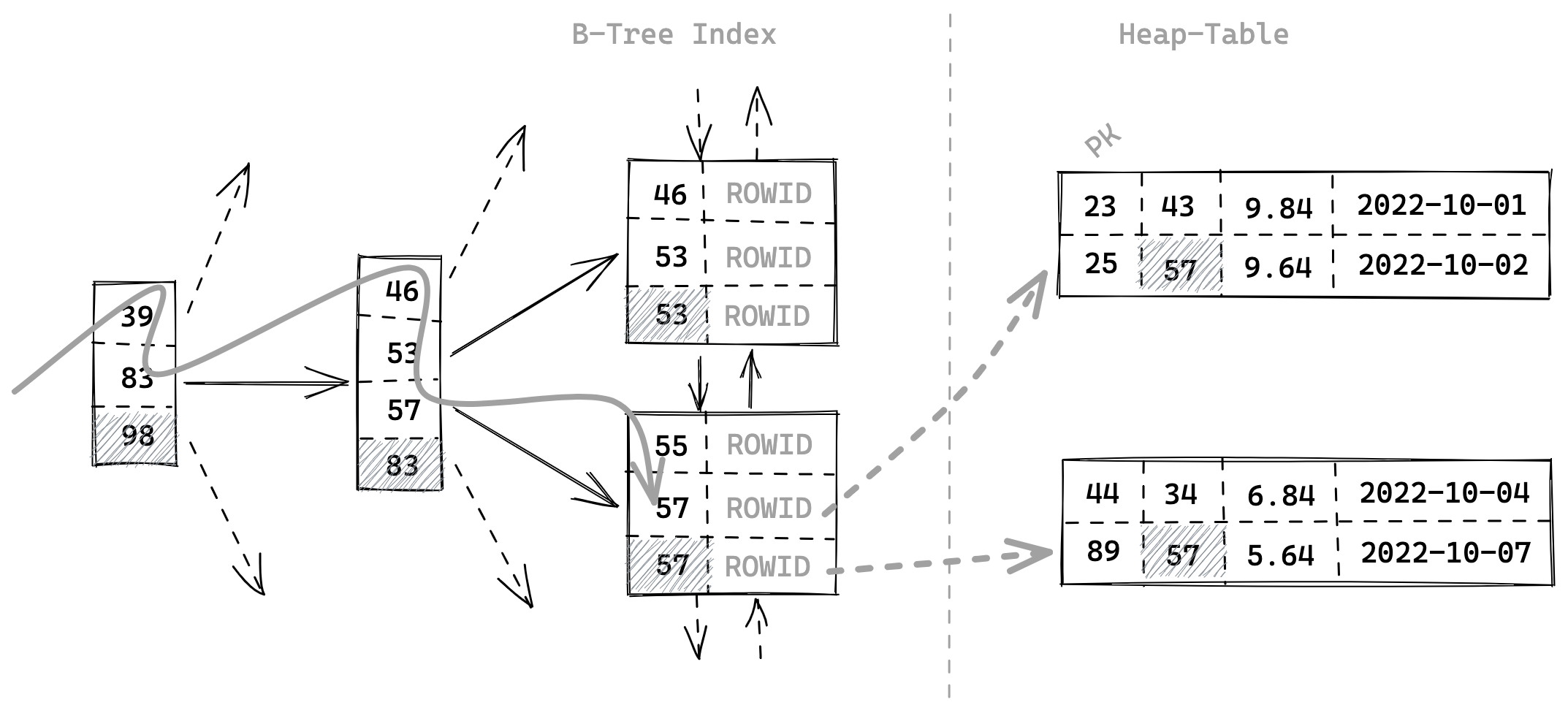
Figure 2: index-based-access-on-a-heap-table
B-Tree 的上级 leaf nodes 存储的是下级 leaf nodes 中列值的最大值,可以从图中看出最底层的 leaf nodes 存储的是 ROWID,可以据此查找到堆表中的位置。
索引组织表 (Clustered Indexes / Index Organized Tables (IOT))
Some databases can indeed use an index as primary table store. The Oracle database calls this concept index-organized tables (IOT), other databases use the term clustered index. In this section, both terms are used to either put the emphasis on the table or the index characteristics as needed.
An index-organized table is thus a B-tree index without a heap table. This results in two benefits: (1) it saves the space for the heap structure; (2) every access on a clustered index is automatically an index-only scan.
索引组织表以主键顺序组织物理数据存储,索引结构中的每个叶节点(leaf nodes)都存储着完整的行数据。对应的主键被称为聚簇索引(Clustered Indexes),除此之外的索引称为二级索引(Secondary Indexes)。
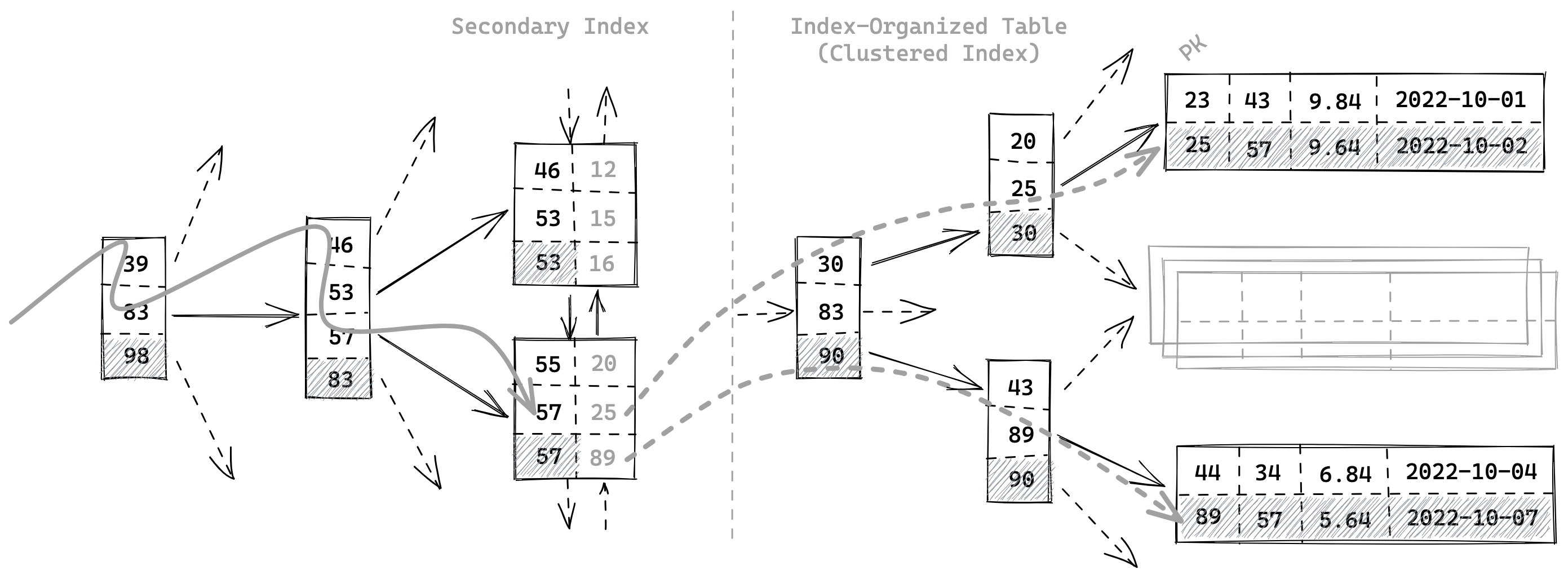
Figure 3: secondary-index-on-an-IOT
聚簇索引
- 在 MySQL 中通常主键即为「聚簇索引」;若没有定义主键,则第一个
NOT NULL UNIQUE列是聚集索引;若没有NOT NULL UNIQUE列,InnoDB 会创建一个隐藏的 row-id 作为聚集索引。 - 聚簇索引是按照索引顺序对物理记录排序,存储完整的行记录。
二级索引
- 除主键外的其他列上新建的索引都是二级索引。
- 二级索引的排序与物理记录的排序不一致,存储的是该列本身排序后的值和主键。
索引组织表的好处
- 可以节省堆表占用的空间
- 访问聚簇索引可以直接获取数据(即「覆盖索引」)
- 二级索引需要回表,即需要根据二级索引的叶节点内的主键,再对主键形成的聚簇索引进行遍历,查找到具体的记录。
索引组织表的缺点
图 secondary-index-on-an-IOT 就是索引组织表中,二级索引获取数据的流程。再次根据主键在索引组织表中遍历查找就叫做「回表」。
各常用的关系型数据库索引类型
MySQL
The MyISAM engine only uses heap tables while the InnoDB engine always uses clustered indexes. That means you do not directly have a choice.
Oracle Database
The Oracle database uses heap tables by default. Index-organized tables can be created using the ORGANIZATION INDEX clause:
CREATE TABLE ( id NUMBER NOT NULL PRIMARY KEY, [...] ) ORGANIZATION INDEX;
The Oracle database always uses the primary key as the clustering key.
PostgreSQL
PostgreSQL only uses heap tables.
You can, however, use the CLUSTER clause to align the contents of the heap table with an index.
SQL Server
By default SQL Server uses clustered indexes (index-organized tables) using the primary key as clustering key. Nevertheless you can use arbitrary columns for the clustering key—even non-unique columns.
To create a heap table you must use the NONCLUSTERED clause in the primary key definition:
CREATE TABLE ( id NUMBER NOT NULL, [...] CONSTRAINT pk PRIMARY KEY NONCLUSTERED (id) );
Dropping a clustered index transforms the table into a heap table.
SQL Server’s default behavior often causes performance problems when using secondary indexes.
联合索引 (Concatenated Indexes)
联合索引遵循「最左匹配原则(Leftmost Index Prefixes)」,MySQL 联合索引创建的时候会对 (a, b) 其中的 a 先进行排序,再在 a 的基础上对 b 进行排序。如果是 (a, b, c) 也是一样的方式。
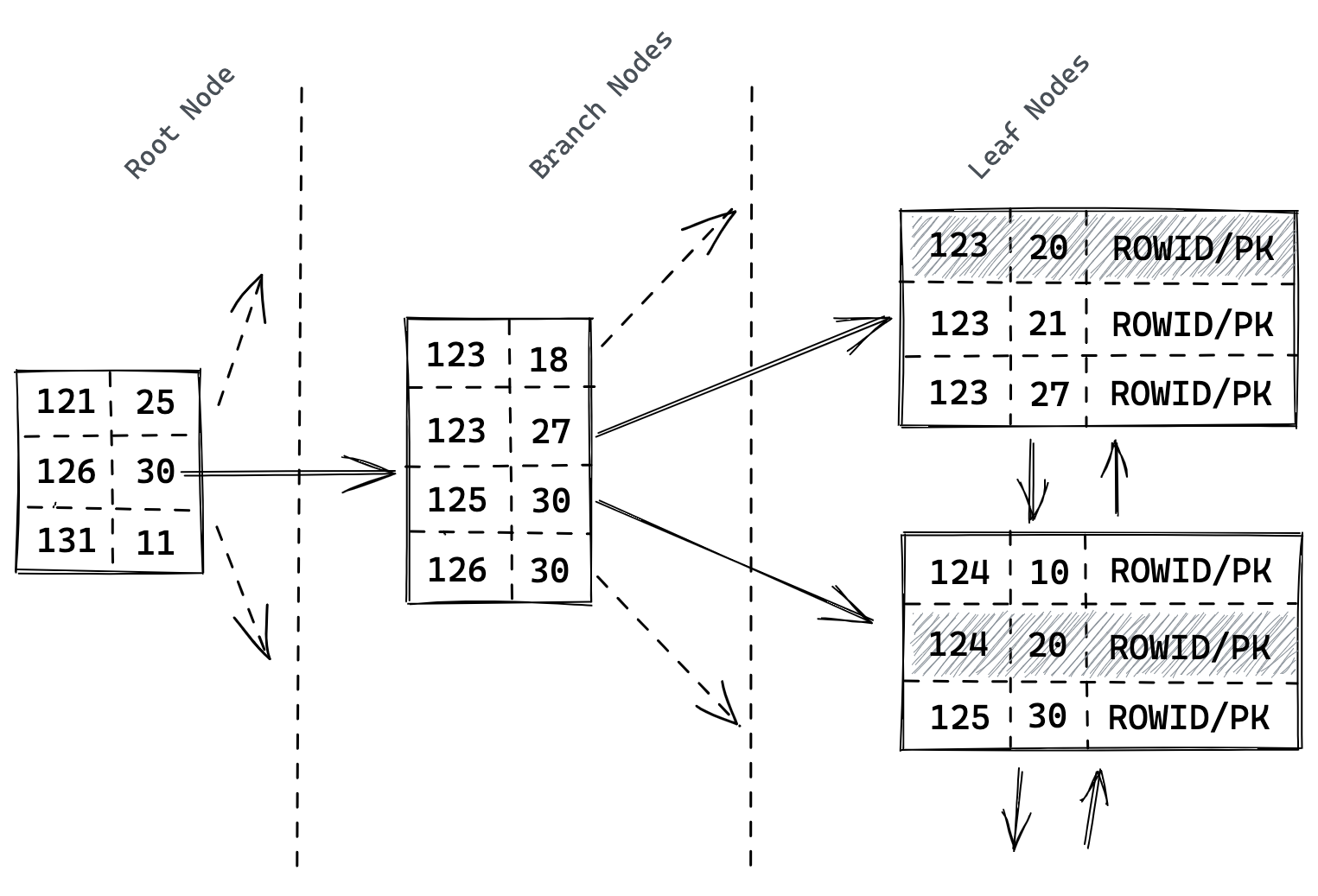
Figure 4: concatenated-indexes
因此,判断是否符合「最左匹配原则」,是否能够使用索引,可以根据底层的索引实现逻辑来进行判断。即,按照创建索引时的顺序,联合索引中的第一个字段是有序的,一旦第一个字段确定值,那么第二个字段也是有序的,以此类推,有序即可用索引,否则不行。
<,>和BETWEEN可以用索引,但是按照上述的逻辑,范围查询字段后的索引字段就无法用上索引,因为范围查询字段的值并没有确定,后续的字段就是无序的。LIKE在"a%"这种右匹配时,会在索引是按照字母排序的情况下用上索引(% 左侧字符合适的情况下也可以建立前缀索引)。至于左匹配和全匹配,按照上述的逻辑,完全是无序的,无法使用索引。WHERE b = ? AND a = ? AND c = ?这种颠倒了顺序的 SQL 是不影响「最左匹配原则」的,数据库执行前,解释器会对其重新排序优化。
References
- Heaps (Tables without Clustered Indexes) - SQL Server | Microsoft Learn
- Markus Winand (2012) SQL Performance Explained Everything Developers Need to Know about SQL Performance